What it does
It audits the signals AI crawlers genuinely consume, scores where you stand, and
generates a clean, reviewable package you can upload as-is.
%
AI-readiness score
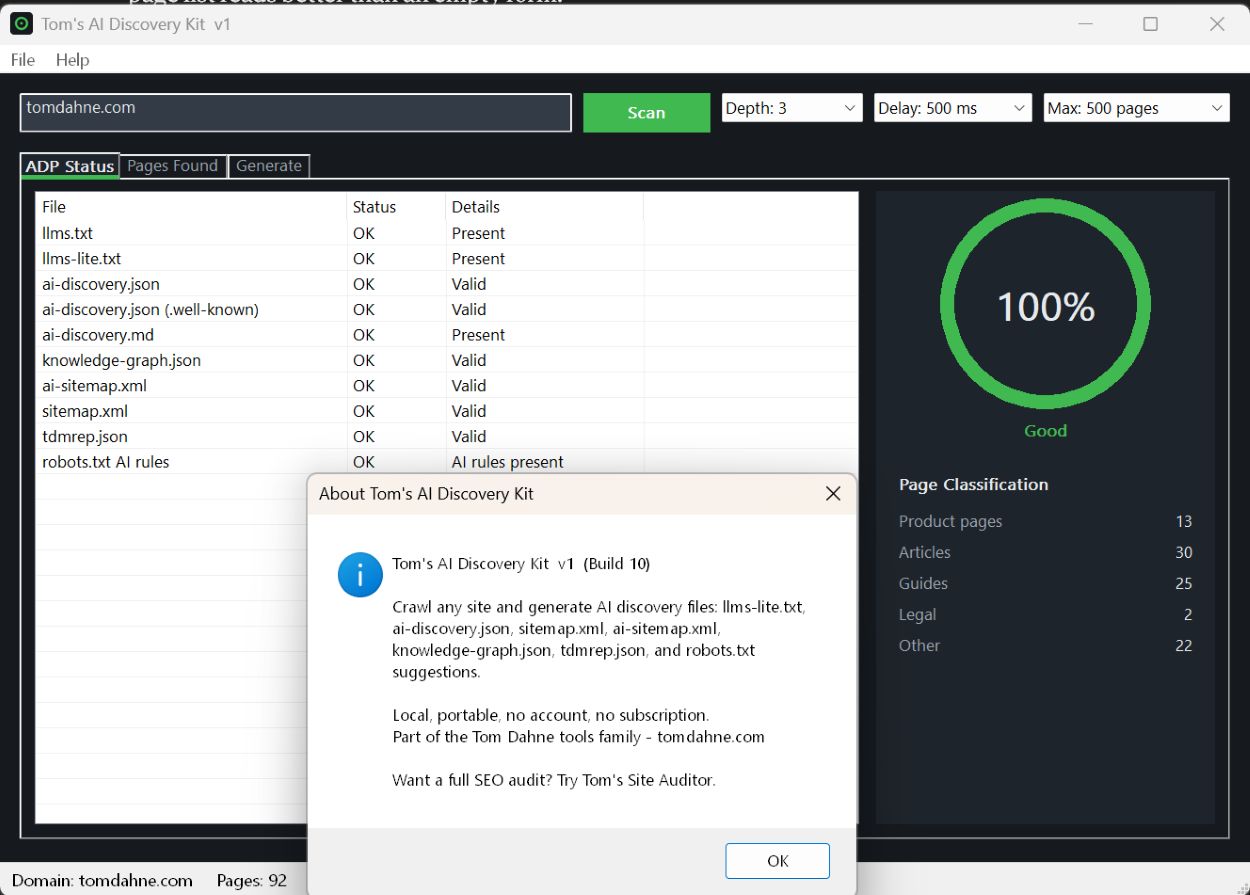
A light crawl checks your site against the AI-discovery and crawler-control
endpoints and gives you one clear percentage — so you know where you stand before
you change anything.
✓
ADP endpoint audit
Probes the standard endpoints — robots.txt AI rules, sitemap.xml, ai-discovery.json,
llms.txt and the rest — and tells you exactly which you already have, which are
missing, and which are misconfigured.
⚙
robots.txt AI-bot rules
Generates explicit allow/deny rules for the AI crawlers that actually respect
robots.txt — GPTBot, ClaudeBot, Google-Extended, PerplexityBot and more. Merges into
an existing file additively, never overwriting your own blocks.
☷
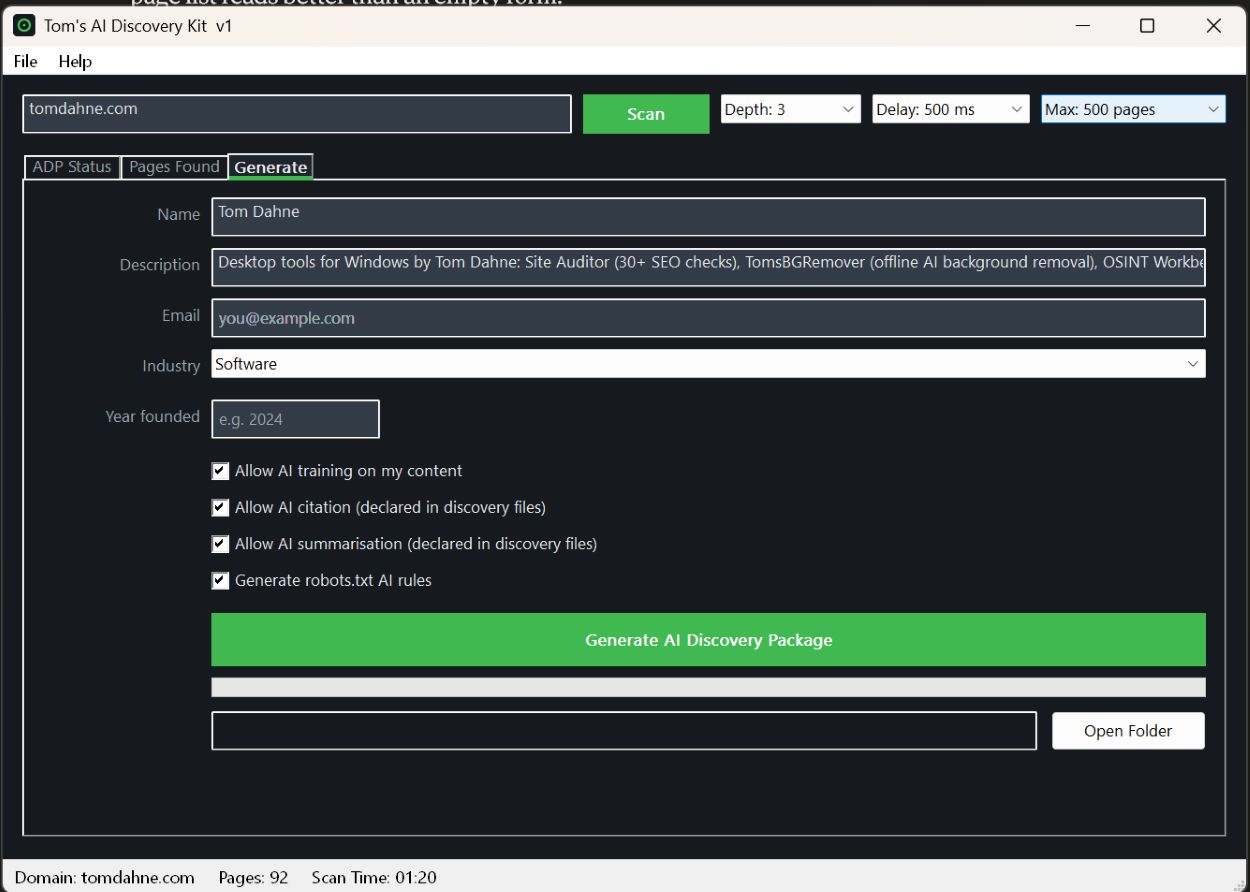
Structured data & knowledge graph
Builds a schema.org structured-data starter and a knowledge-graph.json from what it
finds on your pages — the markup AI engines actually parse when they read your HTML.
⊘
Training opt-out (tdmrep)
Declares your text-and-data-mining position in a standard tdmrep.json,
tied to your training choice so robots.txt and tdmrep agree. Your stance, stated
unambiguously.
☰
Sitemaps
Produces a clean sitemap.xml and an ai-sitemap.xml from the
crawl, with per-URL last-modified dates — the discovery file AI crawlers fetch most
after robots.txt.
≡
The llms.txt family — honestly
Generates llms.txt, llms-lite.txt,
ai-discovery.json and ai-discovery.md too — included as
forward-looking extras, with a plain note on what current adoption data actually shows.
▤
Page classification
Labels every page it finds — product, article, guide, utility, legal, or index — so
the generated files describe your site accurately instead of treating every URL the same.
🔒
Private by design
The crawl runs from your machine and the package is written to a folder next to the
EXE. No account, no telemetry, nothing uploaded. The only network traffic is the
crawl of the site you point it at.
An honest word on llms.txt. Server-log evidence — including my own —
shows the major AI crawlers reach sites through robots.txt, sitemaps, and your HTML, and
rarely fetch the llms.txt-style files. This kit leads with the signals that work and
includes the convention files as cheap, static insurance — not as a magic visibility
lever. Read the data →